Honest admission: It's been so so long since my last blog post. I write these posts to prove I know what I'm talking about when I present myself as a software engineering and deep learning professional. I don't write them for an audience, except for the occasional visitor that could pick up a good idea or two from my projects, or hiring manager that wants to see that this isn't my first rodeo.
Onto Briefly…
This project is an experiment in orchestrating tool-based reasoning using large language models (LLMs). The goal was to create a minimal, extensible investment advisor that can provide portfolio-specific guidance using real-time data – without baking financial logic directly into the model or the code.
The core idea is to give the LLM access to tools for memory, portfolio data, and market news – and let it decide what to use. The actual logic lives in both hardcoding essential advisor logic and LLM-based orchestration which is driven by structured tool calls via the Model Context Protocol (MCP).
Motive
I wanted to prototype something that could reason and generate text – by composing information from multiple sources. The result is a lightweight, LLM-powered advisor that can:
- determine and recall your investment goals from long-term memory,
- access your current portfolio,
- pull in fresh news related to your holdings,
- and generate advice based on that context – all within a single prompt-response cycle
After initial guidance for the LLM to ascertain the user's query and investment object, decisions are routed dynamically by the LLM. The LLM chooses what tool to call, when, and in what order through provider endpoints.
Tooling and orchestration
The backend is split into three main "tools," each exposed through a simple HTTP interface:
1. Investment memory
Stores a user's stated objective – like maximizing dividend yield or reducing volatility – and keeps it accessible across sessions. The model can query or update this state through a memory provider.
2. Portfolio manager
Handles creation, naming, and editing of portfolios. A portfolio is a structured object – ticker symbols, percentages, optional metadata – and it's stored persistently. The model can request this data when it needs to contextualize advice.
3. News summarizer (External RAG)
Implements a basic retrieval-augmented generation loop. It pulls recent news using keyword tags generated from the prompt, portfolio, and investment objective, then summarizes them, and injects the result into the final prompt template. This keeps the model aware of market conditions without training updates.
The LLM orchestrates all of this. It sees a list of available tools with their input/output schemas and uses the MCP to call them. The frontend's job is just to route and await responses.
Implementation notes
LLM-tool communication and interfaces are powered by FastAPI. The MCP client (the orchestrator) communicates with the backend providers that are tools, via a message loop – it emits a tool call like get_portfolio or fetch_news, and the backend fulfills it, logs it, and returns a structured result.
The frontend is a minimalist focused JS interface – enough to input prompts, create and edit portfolios, and view previous chat results.
MongoDB handles persistence for news summaries for future use. Other data like user memory, portfolios, archived conversations are stored in a SQL database.
Some logic is seeded up front – like guiding the LLM in how to interpret user prompts and goals – but most of the decision-making happens dynamically as the LLM selects and sequences tools through MCP.
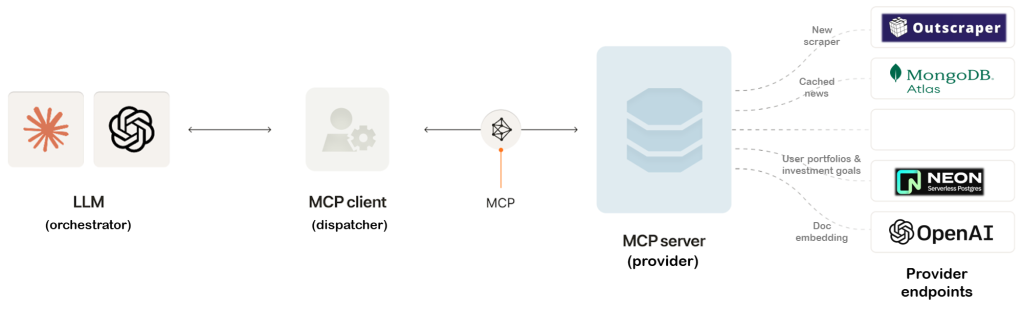
Diagram: Briefly's Model Context Protocol
Why MCP?
Tool calling can be done manually – you can route prompts and engineer workflows – but MCP makes the interaction model declarative and formalized. You define tools once with clear input/output specs, and the model chooses how to use them based on the context.
The advisor may not have a background on the user's memory and so will proactively prompt the user to provide it – the model figures it out dynamically. Likewise, there isn't always a need for retrieval augmentation which is costly, the LLM may decide to provide advice without needing external news data. For example, the user may prompt the advisor to comment on portfolio concentration or strategy which doesn't necessarily need news retrieval.
This makes the architecture modular and extensible.
In the next post, I'll walk through how I implemented MCP in practice.