Creating an Upscaler for Computer Graphics Textures
- Mohamed Benaicha
- Jul 13, 2023
- 6 min read
Updated: Nov 28, 2023
Understanding 3D textures and channel information
Images used as textures for 3D models are often referred to as 3D textures. They're simply greyscale or colored images comprising the pixel-by-pixel information that is mapped to a 3D surface. This 3D surface is the geometry since it is a series of triangles or some other polygonal shape (quadrilaterals) connected at their vertices to create a complete 3D model.
3D textures aren't like traditional images of reality that depict the depth of a scene. 3D textures are intended specifically to be mapped to a flat surface through a process called UV mapping. Depth information is conveyed through an image dedicate to depicting depth information, whereas color information is done by another texture. There are textures that control lighting and shadows. All of these together all called textures maps that in aggregate comprise the material to give a bland 3D model meaning.

Figure 1
For the above reasons, 3D textures aren't treated like normal photo images of reality.

Put simply, upscaling means increasing the resolution of the image. This is done by representing the information of one pixel on a greater number of pixels, say 2 or 4.
Figure 2

This mean you see a lot less of the pixels because an image with greater detail is placed into the same space as the lower quality image.
Figure 3
In order to learn how represent a single pixel as 2 or 4 or even 16 pixels, an AI tool known as a neural network is used that learns how represent areas with edges, areas on the image with a flat color, areas with mixed colors, etc.
A last note, before jumping into the workings of neural networks and how they upscale an image, is that images come in various "modes", based on the channels they have. Some images have a single greyscale channel where each pixel is represented by a value from 0 to 255 with 0 being a black pixel and 255 being a pure white pixel and with value in between representing some shade of grey.
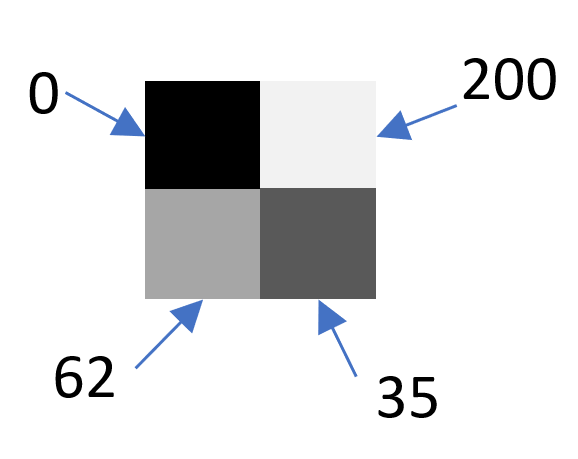
Figure 4
Another image mode is the RGB image mode which an image comprised of 3 channels, reg, green and blue. Each channel represents a spectrum of its color just like a greyscale channel does. A high value on the RGB channels mean a fully saturated (pure) version of that color. In the picture below, a fully saturated pure blue is represented by 255.

Figure 5
Finally, an important image mode for 3D textures is the RGBA image mode which contains the RGB and alpha channel. The alpha channel is just a fourth channel. In non-3D textures, it often depicts transparency in that where the alpha channel is high in value - say 255 - the image's RGB channels on that area of pixels are occluded and are seen as transparent. For programmatic understanding of image channel representation, see A Slightly Deeper Dive Into Image Channel Information.
In the world of 3D textures, the alpha channel is used to indicate transparency, but is used to contain other texture maps. Since the alpha channels contains values like any other channels, from 0 to 255 (or 0, 0.01, 0.02 to 1.0, for images represented by float values), these values can be used to store some information like surface depth, shadow information called ambient occlusion, or even light-related information. The domain of 3D textures is expansive and requires dedicated textbooks, suffice it to say that it is important, when processing 3D textures, that the information on each channel be maintained.
The CG Texture Upscaler does exactly that by handling alpha information on its own and RGB information on its own. This helps preserve information on all of the channels as proven by the demonstrations here.

Figure 6
Deep Learning and Neural Networks
A neural network is a network of transformations that input data goes through to yield a desired output. Let's take the example of a simple image comprising 1 pixel, 1 channel, and a simple neural network that has a single neuron, and a desired output, which is another image comprising a single pixel, a single channel:

Figure 7
A pixel of value 32 must me multiplied by some value w, called the weight, to achieve the target value of 82. This value, for the concerned image (i.e., the image that is a simple pixel with a value 32), is simply 2.5625. But the goal is to be able to get multiple pixels to multiple values which is why multiple weights and neurons are required. The new neural network looks something like this:

Figure 8
We now have to solve the values of 9 weights so that whatever pixels are passed in, the weights can produce the target upscaled image.
In the case of upscaling an input image of 4 by 4 pixels must produce an output image of 8 by 8 or 16 by 16 pixels, hence requiring a lot more weights to be learned. The ESRGAN that is used as the model for the CG Texture Upscaler contains upwards of 16 million such weights. The network part of neural networks becomes more manifest as the task increases in complexity.

Figure 9
Convolutions...
We've seen how simple input data in the form of pixel values are multiplied by a weight that then is outputted as the new pixel value. The CG Texture Upscaler also relies heavily on convolutional layers. The initial RGB channels are transformed where the most important features of the image are extracted. These features are then sent through the neural network as depicted in the diagrams above.
Briefly convolution requires an image channel to be passed through a filter. This filter is itself a collection of weights as those we've seen above. Such weights are what help extract the important features. In the case of upscaling, the features concern the ability to expand a single pixel into 4 pixels while maintaining the same look of the image. To clarify
The orange matrix is a filter of dimensions 3 by 3 which represent weights that are multiplied by the original image (green) in a sliding window fashion. The output image (pink) is the new feature map.



Figure 10
This process is done with other filters that we create. The training process determines the values in the filters. Each filter learns to filter out certain features and generate a new feature map. Generally, each filter outputs 1 feature map. 64 filters should output 64 feature maps. Below, 3 filters produce 3 feature maps, or 3 channels. These could be the RGB channels that we write as the new image, or could be the base set of channels to be processed through another set of filters. This entire process is called convolution and is done many times in large nueral networks such as the ESRGAN used in the CG Texture Upscale.

Figure 11
The output feature maps look very similar to the RGB maps in Figure 9. This means these images are now ready to be passed through another layer or set of layers as per figure 9 in order to arrive at a final output image comprising 3 channels. More details on convolutions can be found here.
The Upscaling Pipeline
The pipeline to upscale an image involves several steps. The image is read and a number of things have to be sorted out before it is sent to the model to be upscaled.
The image must have dimensions that are multiples of 2 or else the model will fail to process it.
A copy of the image is made in order to extract noise later if the user choses to add noise to the final upscaled image.
The CG Texture Upscaler then determines whether the image contains detailed color information to require upscaling using the AI model. Otherwise, images that have equivalent pixels are simply resized to the upscaled dimensions.
The image is converted to the appropriate color space (sRGB) in which the AI model is trained and knows how to upscale. The image's gamma may also be adjusted at this point according to user configuration. The image's bit depth (technically known as data type) is also taken care of at this stage. The AI models takes images of 16- or 32-bit depths (i.e. halfs or floats). Care is taken not to lost information where that can be avoided.
The image is then ready to be upscaled where the RGB channels are upscaled separately from the alpha channels. The decision whether to upscale the image as a whole or in patches is based on user configuration.
After the image is preprocessed and upscaled, some initial transformations have to be reversed and additional features have to be added:
The upscaled image is then converted back to the intended output color space representation as well as the color mode (channels). The images gamma is restored according to the user's configuration.
Following that, noise is added to the image according to user configuration.
Finally the image is written using the format and compression chosen by the user. At this stage, certain image features such as color palettes for bmp formats and mipmaps for dds formats are handled by specialized libraries.

Commentaires